1.图像分类(Object Classification)
识别图片中存在的不同物体的种类(下图,人类、羊类、狗类)

2.分类+定位(Localization and Dection)
分类+定位的任务要求我们在给图片打标签之后,还要框出物体在什么地方(注意与物体检测的区别,在分类定位中,输出的框的个数是事先已知的,而物体检测中则是不确定的)。如下:

常用框架
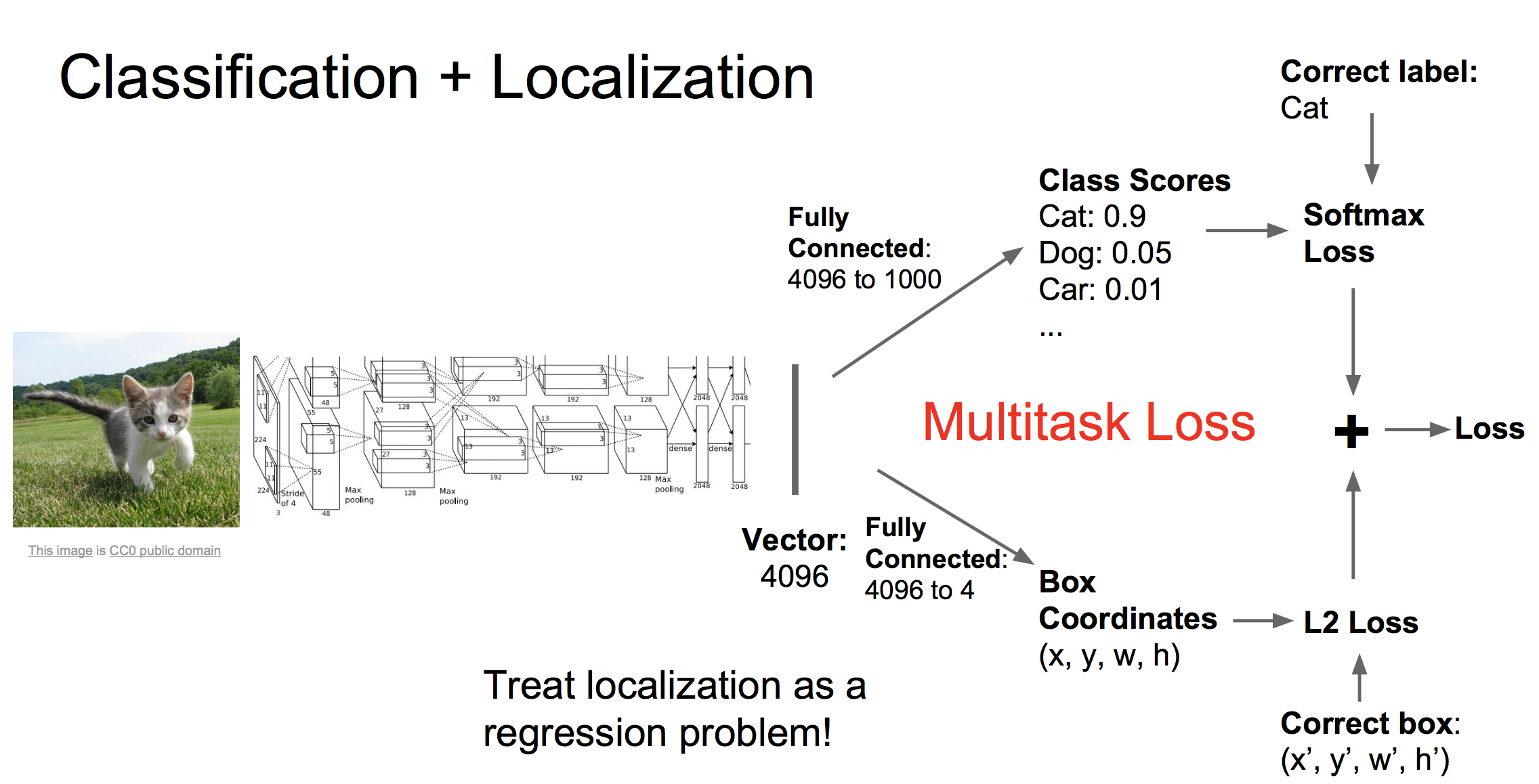
首先我们还是用CNN得到描述图片的特征向量,然后我们接入两个全连接网络,一个网络负责生成最后的类别评分,另一个负责生成红框四个点的坐标值。因此对应两个损失,softmax损失和回归损失。我们将这两个损失加权相加得到总的损失(加权值是超参数),然后进行反向传播学习。
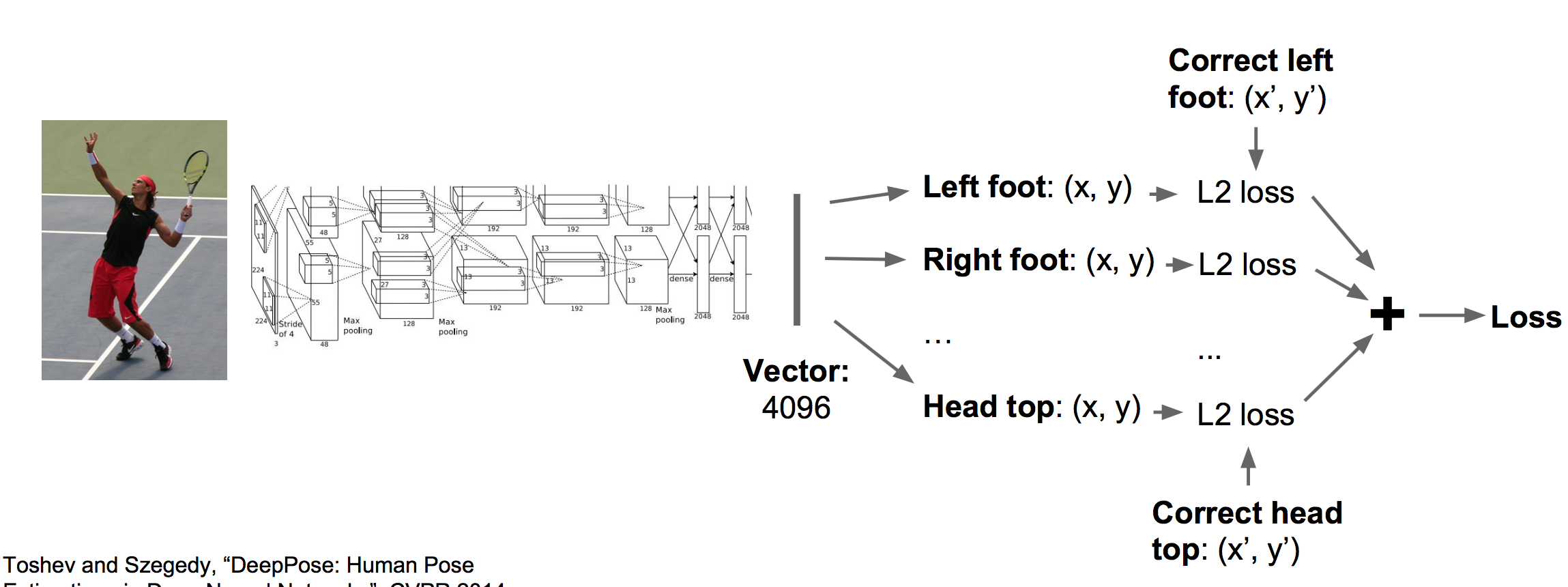
这里应用回归的思路同样可以应用于姿态估计,我们用十四个点来确定一个人的姿态情况:

应用同样的框架(CNN+回归全连接网络)可以训练这个任务:
3.目标检测(Object Detection)

与分类+定位任务不同的是,物体检测中需要检测的物体数量是不确定的,因此无法直接使用上面的回归框架。需要识别图片中的物体及其位置,把它们用矩形框框起来。下面简单介绍几个框架。
常用算法
R-CNN(速度慢,过程繁琐,训练所需空间大)
Faster R-CNN(比前者更准确、快速、简便,但还是不够快,不够简洁)
YOLO的目标检测的算法(速度快,泛化能力强,但精度低,小目标和邻近目标检测效果差,比Fast R-CNN定位误差大一些)
4.语义分割(Semantic Segmentation)
语义分割的任务是对输入的图像进行逐像素的分类,标记出像素级别的物体。同一物体的不同实例不需要单独分割出来。

卷积
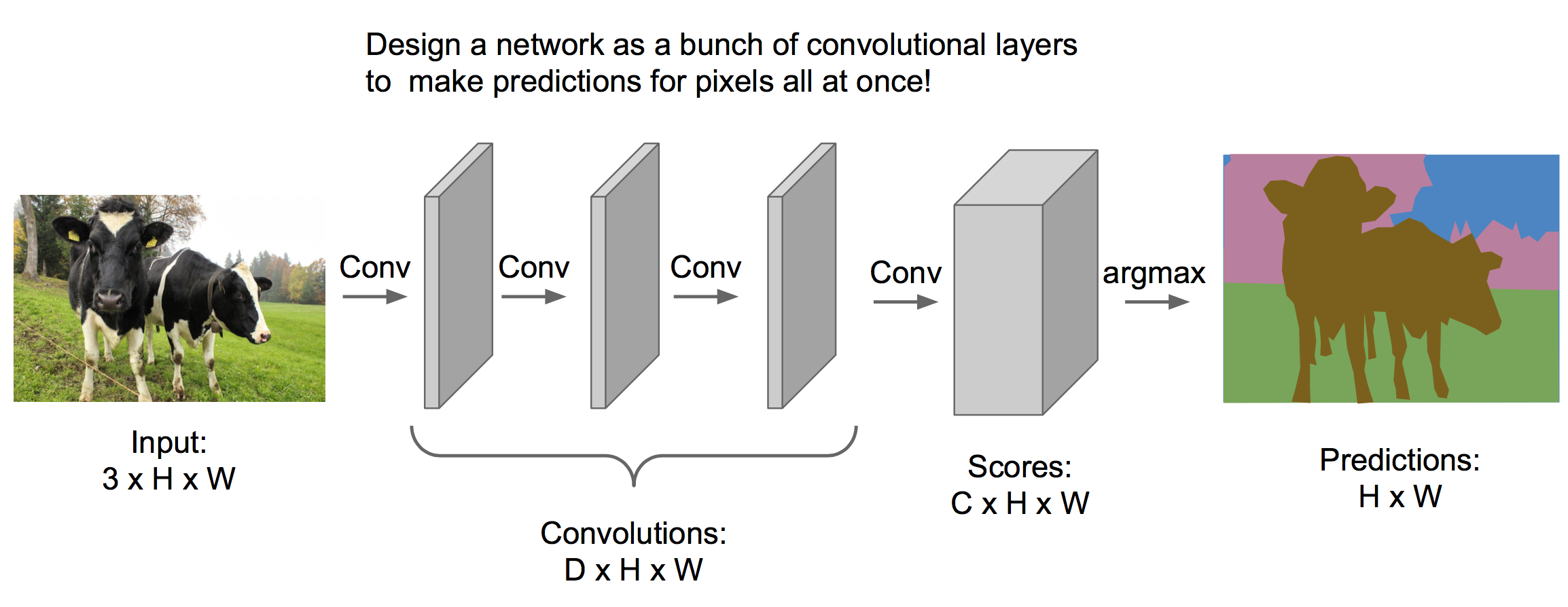
经过多个卷积层处理,最终输出体的维度是C*H*W,C表示类别个数,表示每个像素在不同类别上的得分。最终取最大得分为预测类别。
训练这样一个模型,我们需要对每个像素都分好类的训练集(通常比较昂贵)。然后前向传播出一张图的得分体(C*H*W),与训练集的标签体求交叉熵,得到损失函数,然后反向传播学习参数。
然而,这样一个模型的中间层完全保留了图像的大小,非常占内存,因此有下面改进的框架。
欠采样再过采样
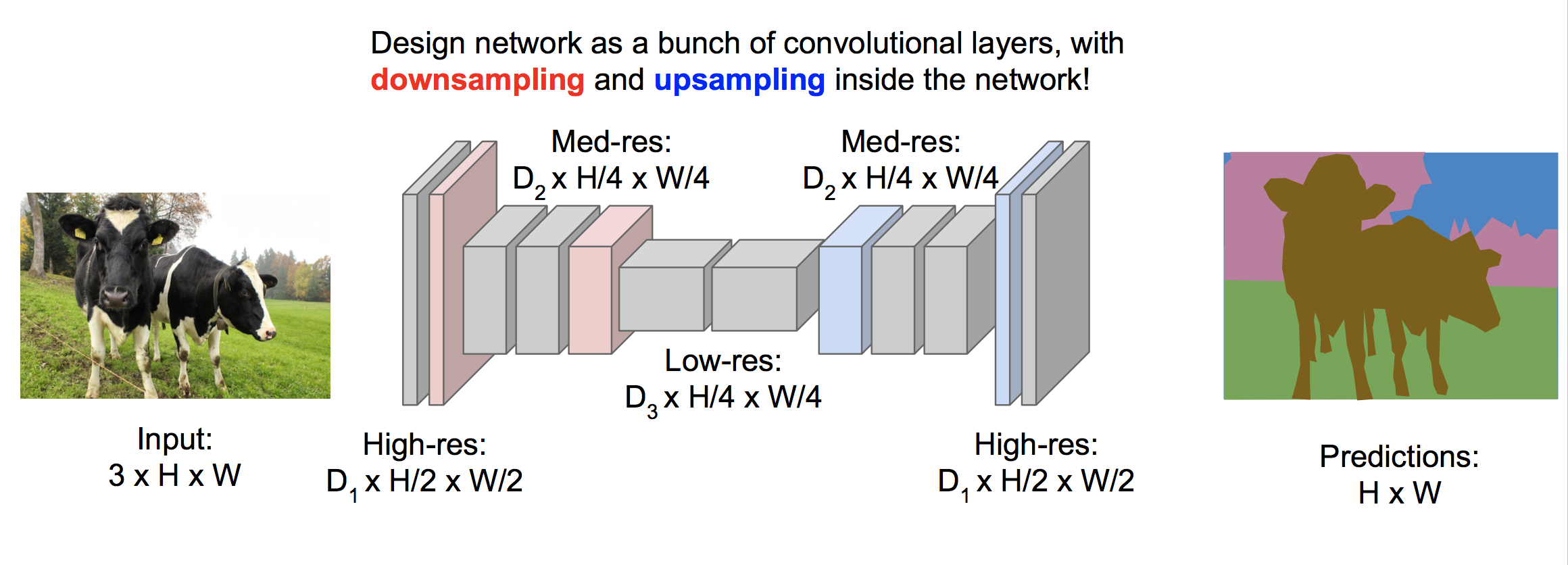
经过欠采样后可以大量节省内存,提高效率,最后再经过过采样来恢复原始图片的大小。我们知道欠采样可以使用卷积层和池化,下面介绍过采样的几种方式。
5.实例分割(Instance Segmentation)
其实就是目标检测和语义分割的结合。相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体(羊1,羊2,羊3)(和语义分割相似,不过相同的类中用不同的颜色区分成羊12345)

Mask RCNN是当前很前沿的一种方法,其将faster RCNN和语义分割结合成一个框架,具有非常好的效果!物体分割要做的是在物体检测上更进一步,从像素层面把各个物体分割出来。
常用算法
是Mask R-CNN、Fast-CNN、DeepMask
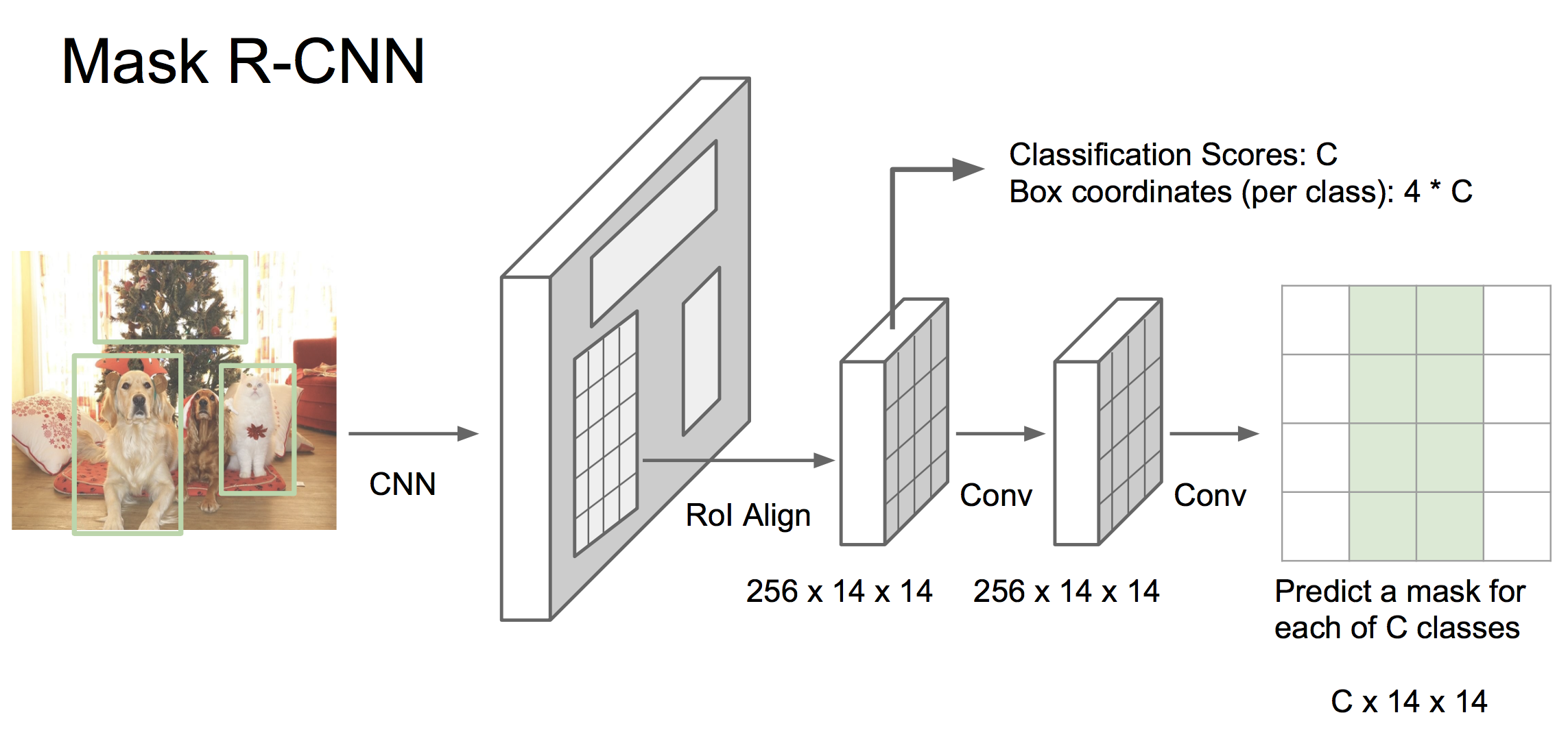
如上图,首先将图像使用CNN处理为特征,然后经过一个RPN网络生成候选区域,投射到之前的feature map。到这里与faster RCNN一样。之后有两个分支,一个分支与faster RCNN相同,预测候选框的分类和边界值,另一个分支则与语义分割相似,为每个像素做分类。
mask RCNN具有超级好的效果,有机会一定要拜读一下。
