基础指标
| 预测值 | |||
| True | False | ||
| 真 实 值 | True | TP 被正确地划分为正例的个数 即实际为正例且被分类器划分为正例的实例数 True ->True | TN 被错误地划分为负例的个数 即实际为正例但被分类器划分为负例的实例数 True ->False |
| False | FP 被错误地划分为正例的个数 即实际为负例但被分类器划分为正例的实例数 False ->True | FN 被正确地划分为负例的个数 即实际为负例且被分类器划分为负例的实例数 False ->False | |
比如我有10张图,5张猫,5张狗,我全部预测为猫,猫预测全对,精确度:5/(5+0)=100%。同理,剩下5张狗也也预测为了猫,召回率:5/(5+5) = 50%
precision 准确率(P)
预测样本中实际正样本数 / 所有的正样本数
公式: precision=TP/(TP+FP)
recall 召回率(R)
预测样本中实际正样本数 / 预测的样本数
公式: Recall=TP/(TP+FN)=TP/P
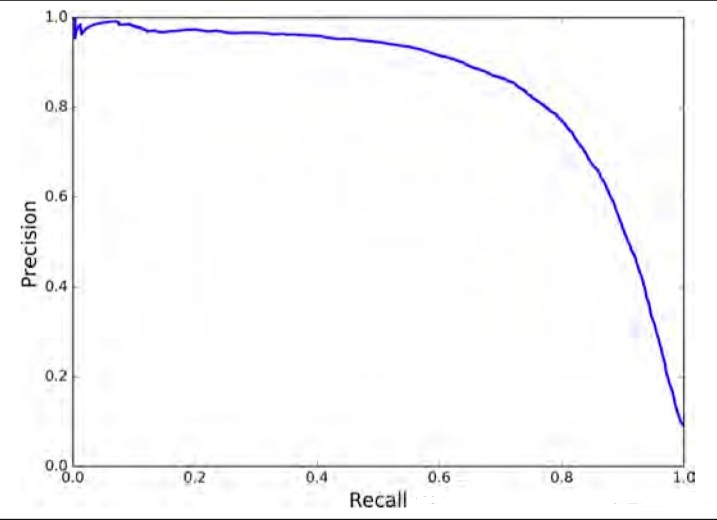
P-R曲线
P-R曲线即 以 precision 和 recall 作为 纵、横轴坐标 的二维曲线。通过选取不同阈值时对应的精度和召回率画出。一般来说,precision和recall是鱼与熊掌的关系,往往召回率越高,准确率越低
AP值
P-R曲线围起来的面积就是AP值,通常来说一个越好的分类器,AP值越高
mAP 多分类
就是所有类AP的平均值
IOU(交并比)
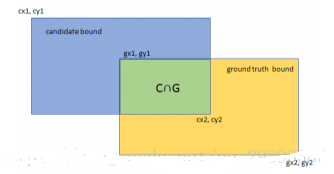
Intersection-over-Union 是目标检测中使用的一个概念,是一种测量在特定数据集中检测相应物体准确度的一个标准。IOU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。